Species Distribution Modeling using Spatial Point Processes: a Case Study of Sloths in Costa Rica
Paula Moraga
Paula Moraga
Materials based on the book Spatial Statistics for Data Science (2023, Chapman & Hall/CRC)
http://www.paulamoraga.com/book-spatial
1 Abstract
Species distribution models are widely used in ecology for conservation management of species and their environments. This paper demonstrates how to fit a log-Gaussian Cox process model to predict the intensity of sloth occurrence in Costa Rica, and assess the effect of climatic factors on spatial patterns using the R-INLA package. Species occurrence data are retrieved using spocc, and spatial climatic variables are obtained with raster. Spatial data and results are manipulated and visualized by means of several packages such as raster and tmap. This tutorial provides an accessible illustration of spatial point process modeling that can be used to analyze data that arise in a wide range of fields including ecology, epidemiology and the environment.
A version of this tutorial appears in Moraga, P. Species Distribution Modeling using Spatial Point Processes: a Case Study of Sloth Occurrence in Costa Rica. The R Journal, 12(2):293-310, 2020.
2 Introduction
Species distribution models are widely used in ecology to predict and understand spatial patterns, assess the influence of climatic and environmental factors on species occurrence, and identify rare and endangered species. These models are crucial for the development of appropriate strategies that help protect species and the environments where they live.
In this paper, we demonstrate how to formulate spatial point processes for species distribution modeling and how to fit them with the R-INLA package (Rue, Martino, and Chopin 2009). Point processes are stochastic models that describe the locations of events of interest and possibly some additional information such as marks that inform about different types of events (Diggle 2013; Moraga and Montes 2011). These models can be used to identify patterns in the distribution of the observed locations, estimate the intensity of events (i.e., mean number of events per unit area), and learn about the correlation between the locations and spatial covariates.
The simplest theoretical point process model is the homogeneous Poisson process. This process satisfies two conditions. First, the number of events in any region \(A\) follows a Poisson distribution with mean \(\lambda |A|\), where \(\lambda\) is a constant value denoting the intensity and \(|A|\) is the area of region \(A\). And second, the number of events in disjoint regions are independent. Thus, if a point pattern arises as a realization of an homogeneous Poisson process, an event is equally likely to occur at any location within the study region, regardless of the locations of other events.
In many situations, the homogeneous Poisson process is too restrictive. A more interesting point process model is the log-Gaussian Cox process which is typically used to model phenomena that are environmentally driven (Diggle et al. 2013). A log-Gaussian Cox process is a Poisson process with a varying intensity which is itself a stochastic process of the form \(\Lambda(s) = exp(Z(s))\) where \(Z = \{Z(s): s \in \mathbb{R}^2\}\) is a Gaussian process. Then, conditional on \(\Lambda(s)\), the point process is a Poisson process with intensity \(\Lambda(s)\). This implies that the number of events in any region \(A\) is Poisson distributed with mean \(\int_A \Lambda(s)ds\), and the locations of events are an independent random sample from the distribution on \(A\) with probability density proportional to \(\Lambda(s)\). The log-Gaussian Cox process model can also be easily extended to include spatial explanatory variables providing a flexible approach for describing and predicting a wide range of spatial phenomena.
In this paper, we formulate and fit a log-Gaussian Cox process model for sloth occurrence data in Costa Rica that incorporates spatial covariates that can influence the occurrence of sloths, as well as random effects to model unexplained variability. The model allows to estimate the intensity of the process that generates the data, understand the overall spatial distribution, and assess factors that can affect spatial patterns. This information can be used by decision-makers to develop and implement conservation management strategies.
The rest of the paper is organized as follows. First, we show how to retrieve sloth occurrence data using the spocc package (Chamberlain 2018) and spatial climatic variables using the raster package (Hijmans 2019). Then, we detail how to formulate the log-Gaussian Cox process and how to use R-INLA to fit the model. Then, we inspect the results and show how to obtain the estimates of the model parameters, and how to create create maps of the intensity of the predicted process. Finally, the conclusions are presented.
3 Sloth occurrence data
Sloths are tree-living mammals found in the tropical rain forests of Central and South America. They have an exceptionally low metabolic rate and are noted for slowness of movement. There are six sloth species and two types, two-toed and three-toed sloths. Here, we use the R package spocc (Chamberlain 2018) to retrieve occurrence data of the three-toed brown-throated sloth in Costa Rica. spocc provides functionality for retrieving and combining species occurrence data from many data sources such as from the Global Biodiversity Information Facility (GBIF) and th Atlas of Living Australia (ALA).

We use the occ() function from spocc to retrieve the locations of brown-throated sloth in Costa Rica recorded between 2000 and 2019 from GBIF.
In the function, we specify arguments query with the species scientific name (Bradypus variegatus), from with the name of the database (GBIF), and date with the start and end dates (2000-01-01 to 2019-12-31).
We also specify we wish to retrieve occurrences in Costa Rica by setting gbifopts to a named list with
country equal to the 2-letter code of Costa Rica (CR).
Moreover, we only retrieve occurrence data that have coordinates by setting has_coords = TRUE, and specify limit equal to 1000 to retrieve a maximum of 1000 occurrences.
library('spocc')
df <- occ(query = 'Bradypus variegatus', from = 'gbif',
date = c("2000-01-01", "2019-12-31"),
gbifopts = list(country = "CR"),
has_coords = TRUE, limit = 1000)The output of occ() is of class occdat and has slots for each of data sources. We can see the slots names by typing names(df).
## [1] "gbif" "inat" "ebird" "vertnet" "idigbio" "obis" "ala"In this case, since we only retrieve data from GBIF, the only slot with data is df$gbif while the others are empty.
df$gbif contains information about the species occurrence and also other details about the retrieval process.
We can use the occ2df() function to combine the output of occ() and create a single data frame with the most relevant information for our analysis, namely, the species name, the decimal degree longitude and latitude values, the data provider, and the dates and keys of the occurrence records.
A summary of the data can be seen with summary(d). We observe the data contain 1000 locations of sloths occurred between 2008-01-08 and 2020-12-08.
## name longitude latitude prov
## Length:1000 Min. :-85.51 Min. : 8.340 Length:1000
## Class :character 1st Qu.:-84.14 1st Qu.: 9.389 Class :character
## Mode :character Median :-84.01 Median : 9.781 Mode :character
## Mean :-83.86 Mean : 9.879
## 3rd Qu.:-83.51 3rd Qu.:10.451
## Max. :-82.62 Max. :11.036
## date key
## Min. :2008-01-08 Length:1000
## 1st Qu.:2014-02-18 Class :character
## Median :2017-05-05 Mode :character
## Mean :2016-05-23
## 3rd Qu.:2019-01-09
## Max. :2020-12-08We can visualize the locations of sloths retrieved in Costa Rica using several mapping packages such as tmap (Tennekes 2018), ggplot2 (Wickham 2016), leaflet (Cheng, Karambelkar, and Xie 2018), and mapview (Appelhans et al. 2019). Here we choose to create maps using tmap.
First, we use the st_as_sf() function from the sf (Rsf?) package to create a sf object called dpts with the coordinates of the sloth locations.
library(sf)
dpts <- st_as_sf(d[, 2:3], coords = c("longitude", "latitude"))
st_crs(dpts) <- "EPSG:4326"Then we create the map plotting the locations of dpts. tmap allows to create both static and interactive maps by using tmap_mode("plot") or tmap_mode("view"), respectively. Here, we create an interactive map using use a basemap given by the OpenStreetmap provider, and plot the the sloth locations with tm_shape(dpts) + tm_dots().
The map created shows an inhomogeneous pattern of sloths with concentrations in several locations of Costa Rica. We will use a log-Gaussian Cox point process model to predict the intensity of the process that generates the sloth locations and assess the potential effect that climatic variables have on the occurrence pattern.
4 Spatial climatic covariates
In the model, we include a spatial explanatory variable that can potentially affect sloth occurrence.
Specifically, we include a variable that denotes annual minimum temperature observed in the study region.
This variable can be obtained using the geodata package (Rgeodata?) from the WorldClim database (http://www.worldclim.org/bioclim).
We use the worldclim_country() function of the geodata package by specifying the code of the country ("CR"),
the variable name ("tmin"), and a resolution of 10 minutes of a degree ("10").
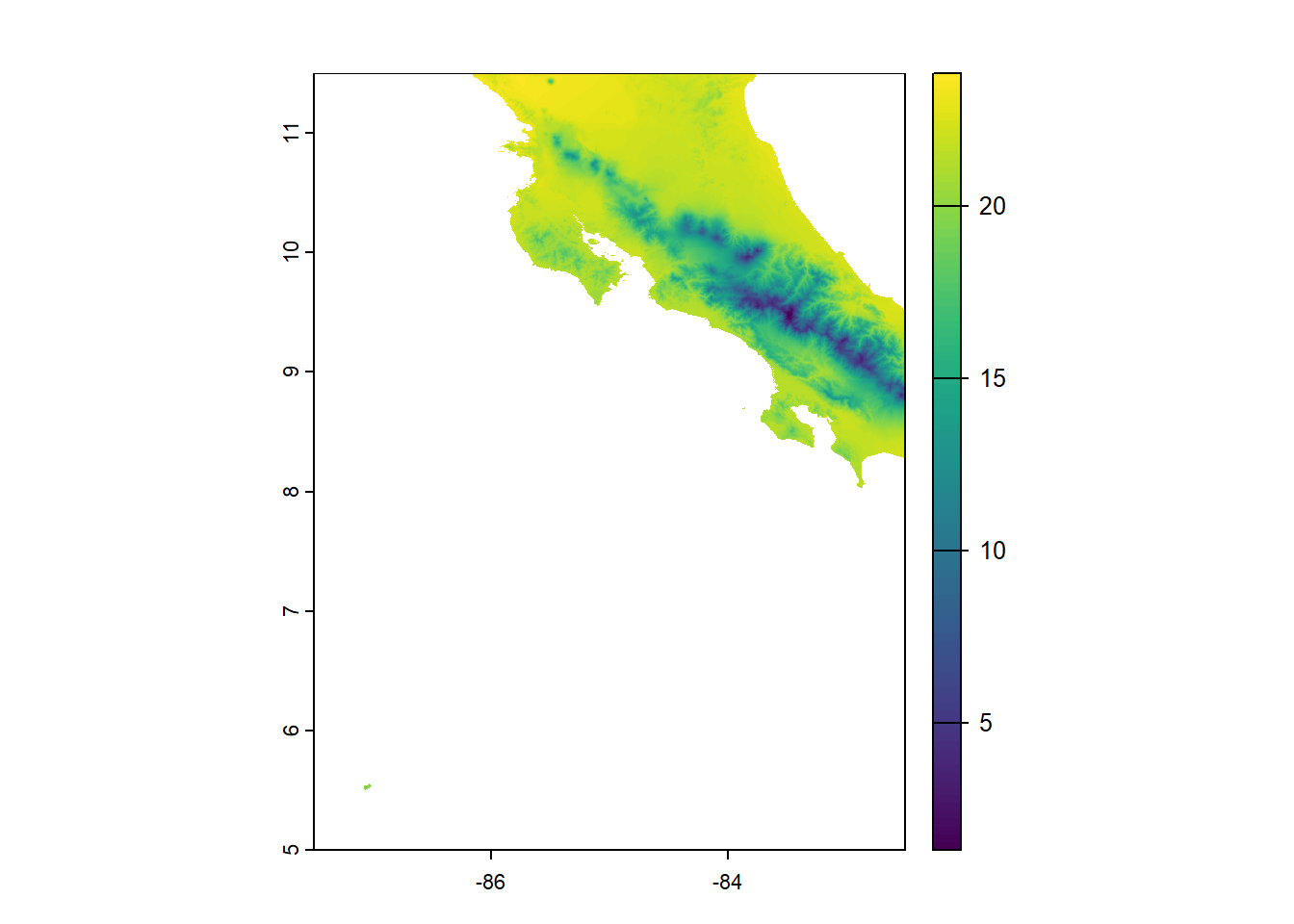
worldclim_country() returns a SpatRaster with minimum temperature observations for each month.
We average the values of the SpatRaster and compute a raster that represents annual average minimum temperature.
library(terra)
rmonth <- geodata::worldclim_country(country = "CR", var = "tmin",
res = 10, path = tempdir())
plot(rmonth)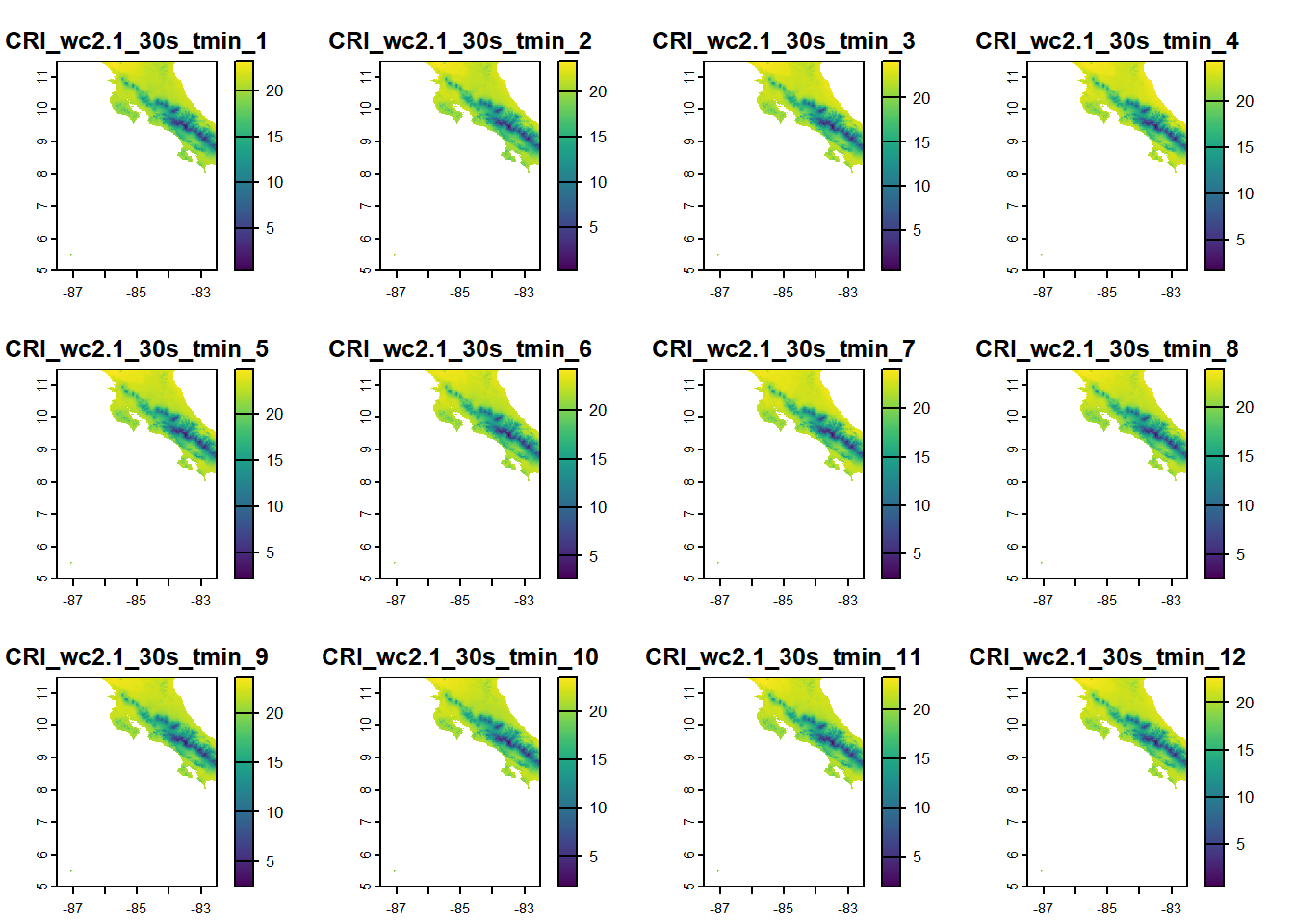
5 Implementing and fitting the spatial point process model
5.1 Log-Gaussian Cox process model
We assume that the spatial point pattern of sloth locations in Costa Rica, \(\{s_i: i=1, \ldots, n\}\), has been generated as a realization of a log-Gaussian Cox process with intensity given by \(\Lambda(s)= exp(\eta(s))\).
This model can be easily fitted by approximating it by a latent Gaussian model by means of a gridding approach (Illian et al. 2012).
First, we discretize the study region into a grid with \(n_1 \times n_2 = N\) cells \(\{s_{ij}\}\), \(i=1,\ldots,n_1,\), \(j=1,\ldots,n_2\).
In the log-Gaussian Cox process, the mean number of events in cell \(s_{ij}\) is given by the integral of the intensity over the cell,
\(\Lambda_{ij}=\int_{s_{ij}} exp(\eta(s))ds\), and
this integral can be approximated by
\(\Lambda_{ij} \approx |s_{ij}| exp(\eta_{ij})\),
where \(|s_{ij}|\) is the area of the cell \(s_{ij}\).
Then, conditional on the latent field \(\eta_{ij}\),
the observed number of locations in grid cell \(s_{ij}\),
\(y_{ij}\), are independent and Poisson distributed as follows:
\[y_{ij}|\eta_{ij} \sim Poisson(|s_{ij}| exp(\eta_{ij})).\]
In our example, we model the log-intensity of the Poisson process as
\[\eta_{ij} = \beta_0 + \beta_1 \times cov(s_{ij}) + f_s(s_{ij}) + f_u(s_{ij}).\]
Here \(\beta_0\) is the intercept,
\(cov(s_{ij})\) is the covariate at \(s_{ij}\), and
\(\beta_1\) is the coefficient of \(cov(s_{ij})\).
f_s() is a spatially structured random effect reflecting unexplained variability that can be specified as a second-order two-dimensional CAR-model on a regular lattice.
f_u() is a unstructured random effect reflecting independent variability in cell \(s_{ij}\).
5.2 Computational grid
In order to fit the model, we create a regular grid that covers the region of Costa Rica.
First, we obtain a map of Costa Rica using the ne_countries() function of the rnaturalearth package (South 2017). In the function we set type = "countries", country = "Costa Rica" and scale = "medium"(scale denotes the scale of map to return and possible options are small, medium and large).
library(rnaturalearth)
map <- ne_countries(type = "countries", country = "Costa Rica", scale = "medium")
plot(map)
Then, we create a raster that covers Costa Rica using terra::rast() where we provide the of map Costa Rica and set resolution = 0.1 to create cells with size of 0.1 decimal degrees.
This creates a raster with 31 \(\times\) 33 = 1023 cells, each having an area equal to 0.1\(^2\) decimal degrees\(^2\) (or 11.132 km\(^2\) at the equator).
resolution <- 0.1
# raster grid covering map
r <- terra::rast(map, resolution = resolution)
print(r)## class : SpatRaster
## dimensions : 31, 33, 1 (nrow, ncol, nlyr)
## resolution : 0.1, 0.1 (x, y)
## extent : -85.90801, -82.60801, 8.070654, 11.17065 (xmin, xmax, ymin, ymax)
## coord. ref. : lon/lat WGS 84 (EPSG:4326)## [1] 31## [1] 33## [1] 1023We initially set to 0 the values of all the grid cells by using r[] <- 0.
Then, we use cellFromXY() to obtain the number of sloths in each of the cells where sloths occur, and assign these counts to each of the cells of the raster.
##
## 45 70 72 78 105 106 108 110 111 113 141 142 146 175 179 180 185 189 209 210
## 8 1 1 12 1 1 1 1 1 1 12 2 2 2 2 2 1 20 1 6
## 211 212 217 218 220 222 223 224 243 244 245 246 247 248 249 250 251 253 255 256
## 35 2 5 1 1 28 39 1 13 34 7 2 1 1 18 33 47 1 2 7
## 275 276 277 278 290 312 316 317 318 319 320 321 322 324 349 350 352 354 355 356
## 4 2 1 6 5 2 3 4 14 15 1 3 1 1 3 16 1 1 1 1
## 382 386 387 389 391 392 412 415 419 424 443 446 447 451 453 459 461 470 481 484
## 5 1 2 17 5 3 1 10 3 1 2 1 2 1 1 3 2 1 1 14
## 493 508 512 515 518 527 528 542 546 547 579 580 615 616 617 646 648 649 653 682
## 48 1 1 1 2 35 44 1 2 1 226 1 11 3 2 1 21 5 1 2
## 683 685 687 782 783 784 789 815 817 848 850 852 881 882 883 884 885 915 916 917
## 3 1 1 6 4 1 1 11 1 4 1 1 1 13 3 1 1 2 2 3
## 918 919 950 952
## 7 1 1 4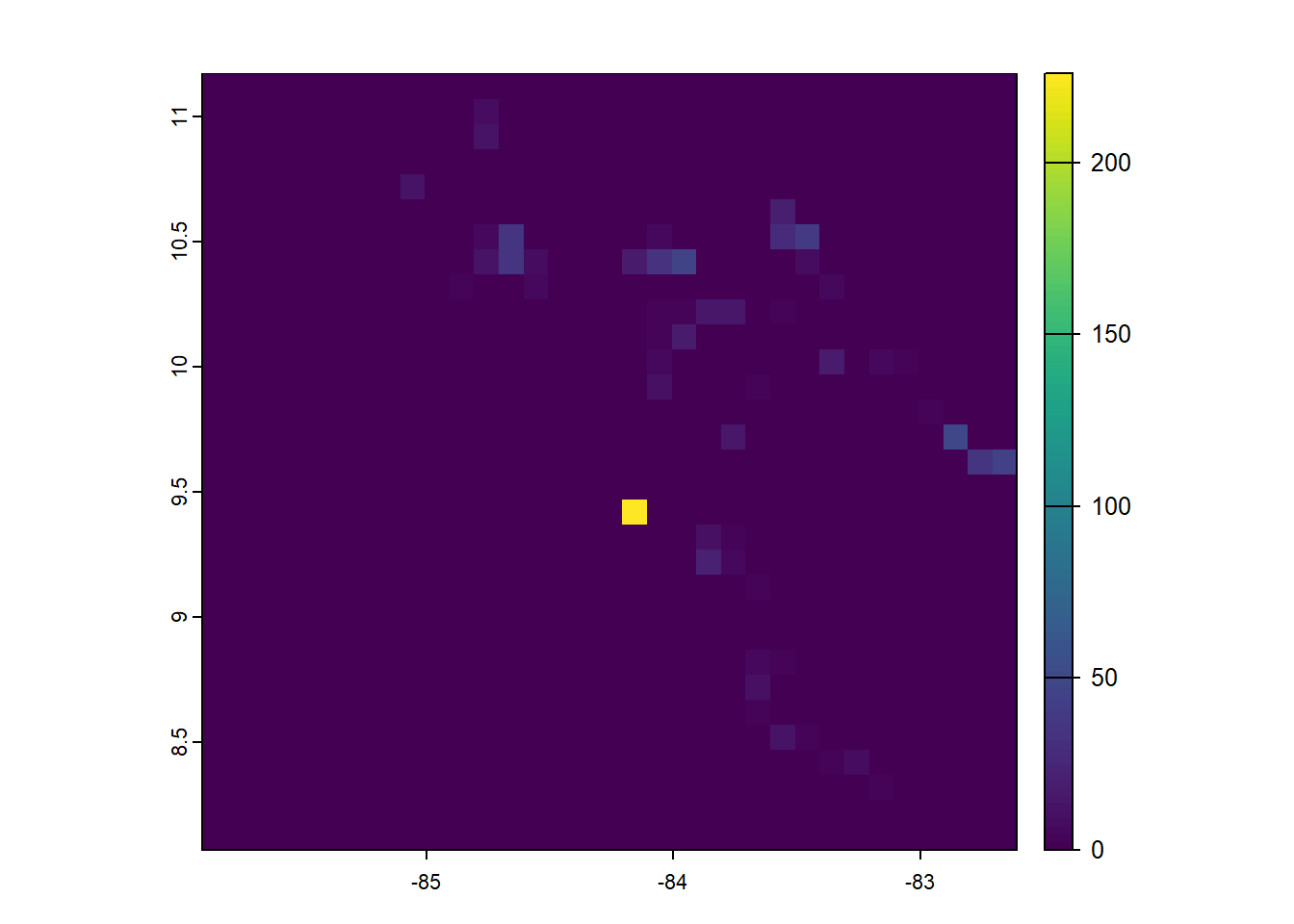
We convert the raster r to a sf object called grid using terra::as.polygons() using aggregate = FALSE to not combine cells with the same values, and sf::st_as_sf() . This grid will be used to fit the model with the R-INLA package.
Finally, we also add a variable cov with the value of the covariate in each of the cells obtained with the extract() function of terra.
5.3 Data
Now, we include in the sf object grid the data needed for modeling. Since the spatial model that will be used in R-INLA assumes data are sorted by columns, we first transpose grid. Then, we add the following variables:
idwith the id of the cells,Ywith the number of sloths, andcellareawith the cell areas.
grid <- grid[as.vector(t(matrix(1:nrow(grid), nrow = ncol, ncol = nrow))), ]
grid$id <- 1:nrow(grid)
grid$Y <- grid$lyr.1
grid$cellarea <- resolution*resolutionFinally, we delete the cells of grid that fall outside Costa Rica.
First, we use sf::st_intersection() to know which cells fall within the map, and then subset these cells in the grid object.
A summary of the data can be seen as follows:
## lyr.1 geometry cov id
## Min. : 0.000 POLYGON :506 Min. : 4.075 Min. : 3.0
## 1st Qu.: 0.000 epsg:4326 : 0 1st Qu.:17.206 1st Qu.: 291.2
## Median : 0.000 +proj=long...: 0 Median :20.596 Median : 565.5
## Mean : 1.966 Mean :18.904 Mean : 533.2
## 3rd Qu.: 0.000 3rd Qu.:21.817 3rd Qu.: 763.8
## Max. :226.000 Max. :23.233 Max. :1009.0
## NA's :62
## Y cellarea
## Min. : 0.000 Min. :0.01
## 1st Qu.: 0.000 1st Qu.:0.01
## Median : 0.000 Median :0.01
## Mean : 1.966 Mean :0.01
## 3rd Qu.: 0.000 3rd Qu.:0.01
## Max. :226.000 Max. :0.01
## We observe that the covariate has some missing values. We decide to impute them with a simple approach where we set these values equal to the mean of the rest of the cells.
## [1] 2 3 4 5 6 8 16 22 43 57 71 86 97 101 111 112 116 127 130
## [20] 142 155 170 186 202 234 265 296 314 315 335 336 337 338 340 341 342 365 366
## [39] 367 385 388 389 390 406 407 410 426 427 428 429 444 445 446 447 448 466 467
## [58] 485 486 497 498 499We use tm_facets(ncol = 2) to display the maps in the same row and two columns, and tm_legend() to put the legends in the left-bottom corner of the plots.
tmap_mode("plot")
tm_shape(grid) +
tm_polygons(col = c("Y", "cov"), border.col = "transparent") +
tm_shape(map) + tm_borders() +
tm_facets(ncol = 2) + tm_legend(legend.position = c("left", "bottom"))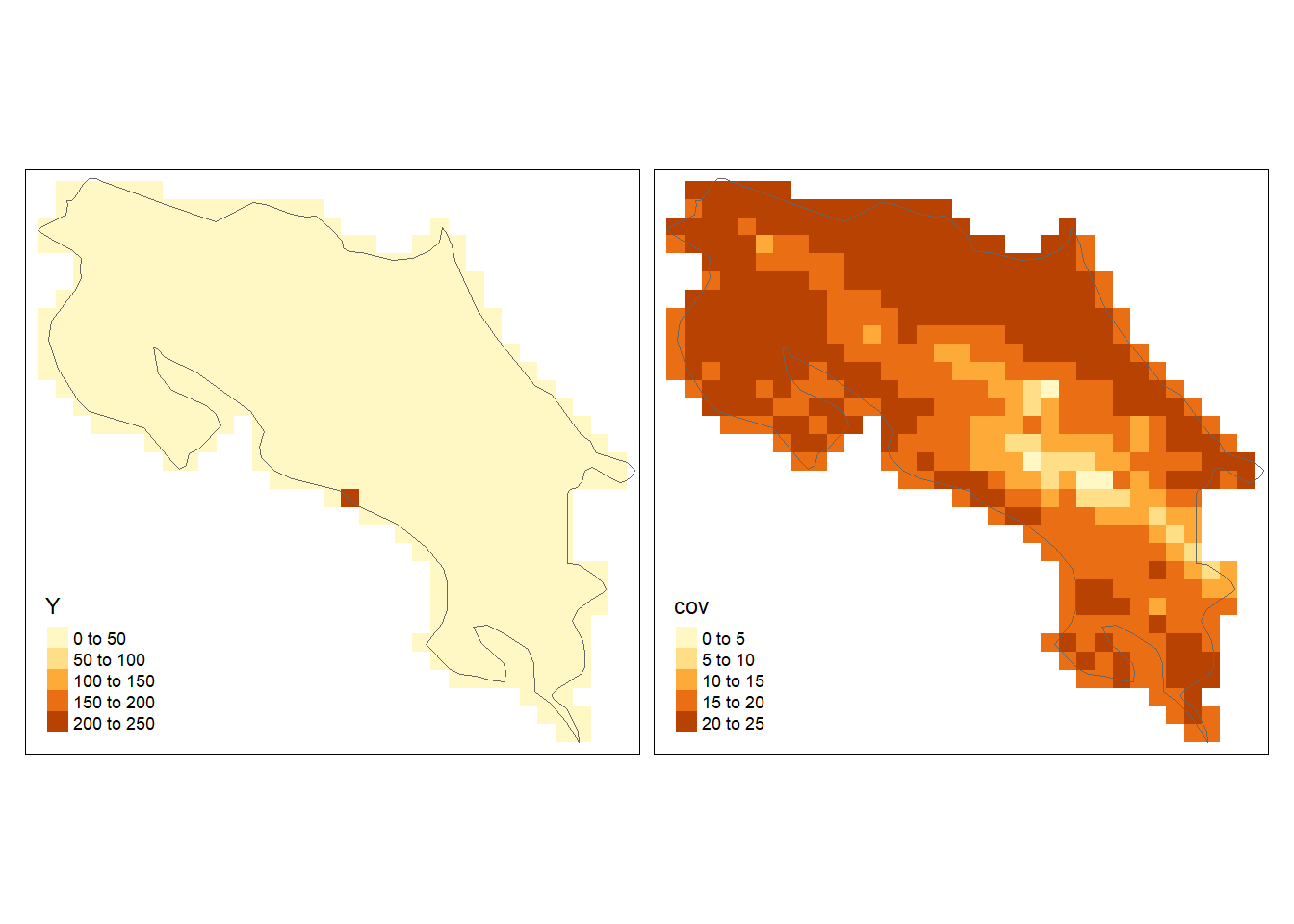
5.4 Fitting the model using INLA
We fit the log-Gaussian Cox process model to the sloths data using the R-INLA package. This package implements the integrated nested Laplace approximation (INLA) approach that permits to perform approximate Bayesian inference in latent Gaussian models (Rue, Martino, and Chopin 2009; Moraga. 2019).
R-INLA is not on CRAN because it uses some external C libraries that make difficult to build the binaries. Therefore, when installing the package, we need to specify the URL of the R-INLA repository as follows:
To fit the model in INLA we need to specify a formula with the linear predictor, and then call the inla() function providing the formula, the family, the data, and other options.
The formula is written by writing the outcome variable,
then the ~ symbol, and then the fixed and random effects separated by + symbols.
By default, the formula includes an intercept.
The outcome variable is Y (the number of occurrences in each cell) and the covariate is cov.
The random effects are specified with the f() function where the first argument is an index vector specifying which elements of the random effect apply to each observation, and the other arguments are the model name and other options.
In the formula, different random effects need to have different indices vectors.
We use grid$id for the spatially structured effect,
and create an index vector grid$id2 with the same values as grid$id
for the unstructured random effect.
The spatially structured random effect with ICAR(2) is specified with the index vector id, the model name that corresponds to ICAR(2) ("rw2d"), and the number of rows (nrow) and columns (ncol) of the regular lattice.
The unstructured random effect is specified with the index vector id2 and the model name "iid".
Finally, we call inla() where we provide the formula, the family (poisson) and the data (grid@data). We write E = cellarea to denote that the expected values in each of the cells are in the variable cellarea of the data.
We also write control.predictor = list(compute = TRUE) to compute the marginal densities for the linear predictor.
5.5 Results
The execution of inla() returns an object res that contains information about the fitted model including the posterior marginals of the parameters and the intensity values of the spatial process.
We can see a summary of the results as follows.
## Time used:
## Pre = 0.577, Running = 2.12, Post = 0.128, Total = 2.83
## Fixed effects:
## mean sd 0.025quant 0.5quant 0.975quant mode kld
## (Intercept) 0.786 1.836 -2.851 0.798 4.358 0.798 0
## cov 0.125 0.071 -0.013 0.125 0.266 0.125 0
##
## Random effects:
## Name Model
## id Random walk 2D
## id2 IID model
##
## Model hyperparameters:
## mean sd 0.025quant 0.5quant 0.975quant mode
## Precision for id 0.378 0.183 0.137 0.340 0.840 0.275
## Precision for id2 0.310 0.060 0.208 0.305 0.444 0.294
##
## Marginal log-Likelihood: -1687.59
## is computed
## Posterior summaries for the linear predictor and the fitted values are computed
## (Posterior marginals needs also 'control.compute=list(return.marginals.predictor=TRUE)')The intercept \(\hat \beta_0=\) 0.786 with a 95% credible interval equal to
(-2.851, 4.358),
the covariate minimum temperature has a positive
effect on the intensity of the process with a posterior mean \(\hat \beta_1=\) 0.125 with a 95% credible interval equal to
(-0.013, 0.266).
We can plot the posterior distribution of the coefficient of the covariate \(\hat \beta_1\) with ggplot2.
First, we calculate a smoothing of the marginal distribution of the coefficient with inla.smarginal() and then call ggplot() specifying the data frame with the marginal values.
library(ggplot2)
marginal <- inla.smarginal(res$marginals.fixed$cov)
marginal <- data.frame(marginal)
ggplot(marginal, aes(x = x, y = y)) + geom_line() +
labs(x = expression(beta[1]), y = "Density") +
geom_vline(xintercept = 0, col = "black") + theme_bw()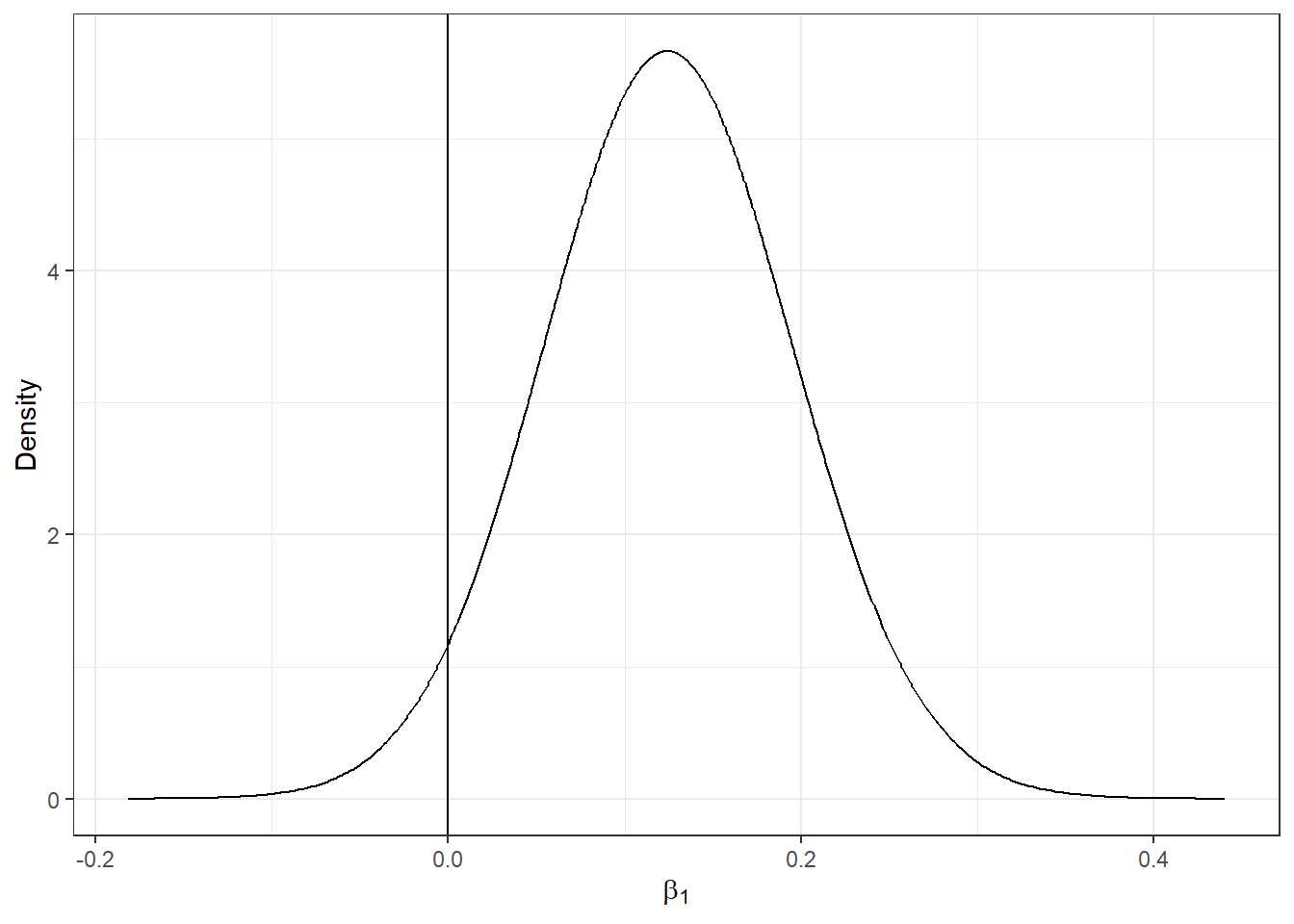
The estimated spatially structured effect can be retrieved with
res$summary.random$id. This contains 1023 elements that correspond to the number of cells in the regular lattice. We can add to grid the posterior mean of the spatial effect corresponding to each of the cells in Costa Rica as follows.
## [1] 1023We can also obtain the posterior mean of the unstructured random effect.
Then we can create maps of the random effects with tmap.
tm_shape(grid) +
tm_polygons(col = c("respa", "reiid"), style = "cont", border.col = "transparent") +
tm_shape(map) + tm_borders() +
tm_facets(ncol = 2) + tm_legend(legend.position = c("left", "bottom"))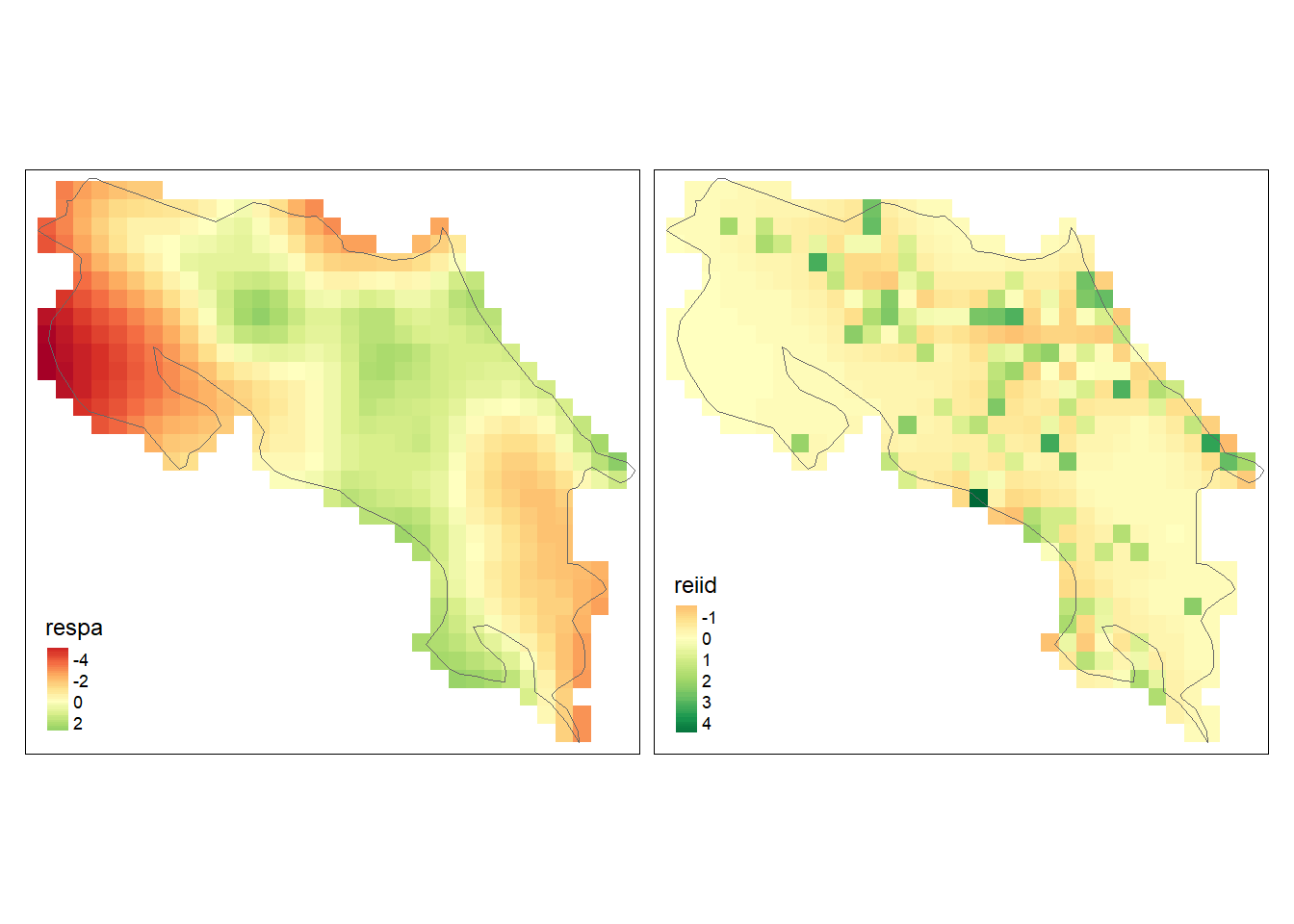
We observe a non-constant pattern of the spatial structured random effect suggesting that the intensity of the process that generates the sloth locations may be affected by other spatial factors that have not been considered in the model. Moreover, the unstructured random effect shows several locations with high values that modify the intensity of the process in individual cells independently of the rest.
The mean and quantiles of the predicted intensity (mean number of events per unit area) in each of the grid cells are in res$summary.fitted.values.
In the object grid, we add a variable NE with the mean number of events of each cell by assigning the predicted intensity multiplied by the cell areas. We also add variables LL and UL with the lower and upper limits of 95% credible intervals for the number of events by assigning quantiles 0.025 and 0.975 multiplied by the cell areas.
cellarea <- resolution*resolution
grid$NE <- res$summary.fitted.values[, "mean"] * cellarea
grid$LL <- res$summary.fitted.values[, "0.025quant"] * cellarea
grid$UL <- res$summary.fitted.values[, "0.975quant"] * cellarea
summary(grid)## lyr.1 geometry cov id
## Min. : 0.000 POLYGON :506 Min. : 4.075 Min. : 3.0
## 1st Qu.: 0.000 epsg:4326 : 0 1st Qu.:17.725 1st Qu.: 291.2
## Median : 0.000 +proj=long...: 0 Median :19.812 Median : 565.5
## Mean : 1.966 Mean :18.905 Mean : 533.2
## 3rd Qu.: 0.000 3rd Qu.:21.702 3rd Qu.: 763.8
## Max. :226.000 Max. :23.233 Max. :1009.0
## Y cellarea id2 respa
## Min. : 0.000 Min. :0.01 Min. : 3.0 Min. :-5.9941
## 1st Qu.: 0.000 1st Qu.:0.01 1st Qu.: 291.2 1st Qu.:-1.7534
## Median : 0.000 Median :0.01 Median : 565.5 Median :-0.3050
## Mean : 1.966 Mean :0.01 Mean : 533.2 Mean :-0.5243
## 3rd Qu.: 0.000 3rd Qu.:0.01 3rd Qu.: 763.8 3rd Qu.: 1.0755
## Max. :226.000 Max. :0.01 Max. :1009.0 Max. : 2.8403
## reiid NE LL UL
## Min. :-1.605337 Min. : 0.1033 Min. : 0.00000 Min. : 0.6255
## 1st Qu.:-0.434447 1st Qu.: 0.3527 1st Qu.: 0.00065 1st Qu.: 2.1973
## Median :-0.141889 Median : 0.5551 Median : 0.00456 Median : 3.4104
## Mean : 0.000801 Mean : 2.4844 Mean : 1.23659 Mean : 5.5949
## 3rd Qu.:-0.010069 3rd Qu.: 1.0632 3rd Qu.: 0.03309 3rd Qu.: 4.8632
## Max. : 4.723147 Max. :225.0499 Max. :197.01765 Max. :255.9290We use tmap to create maps with the mean and lower and upper limits of 95% credible intervals for the number of events.
We plot the three maps with a common legend that has breaks from 0 to the maximum number of cases in grid$UL.
tm_shape(grid) +
tm_polygons(col = c("NE", "LL", "UL"),
style = 'fixed', border.col = "transparent",
breaks = c(0, 10, 50, 100, ceiling(max(grid$UL)))) +
tm_shape(map) + tm_borders() +
tm_facets(ncol = 3) + tm_legend(legend.position = c("left", "bottom")) 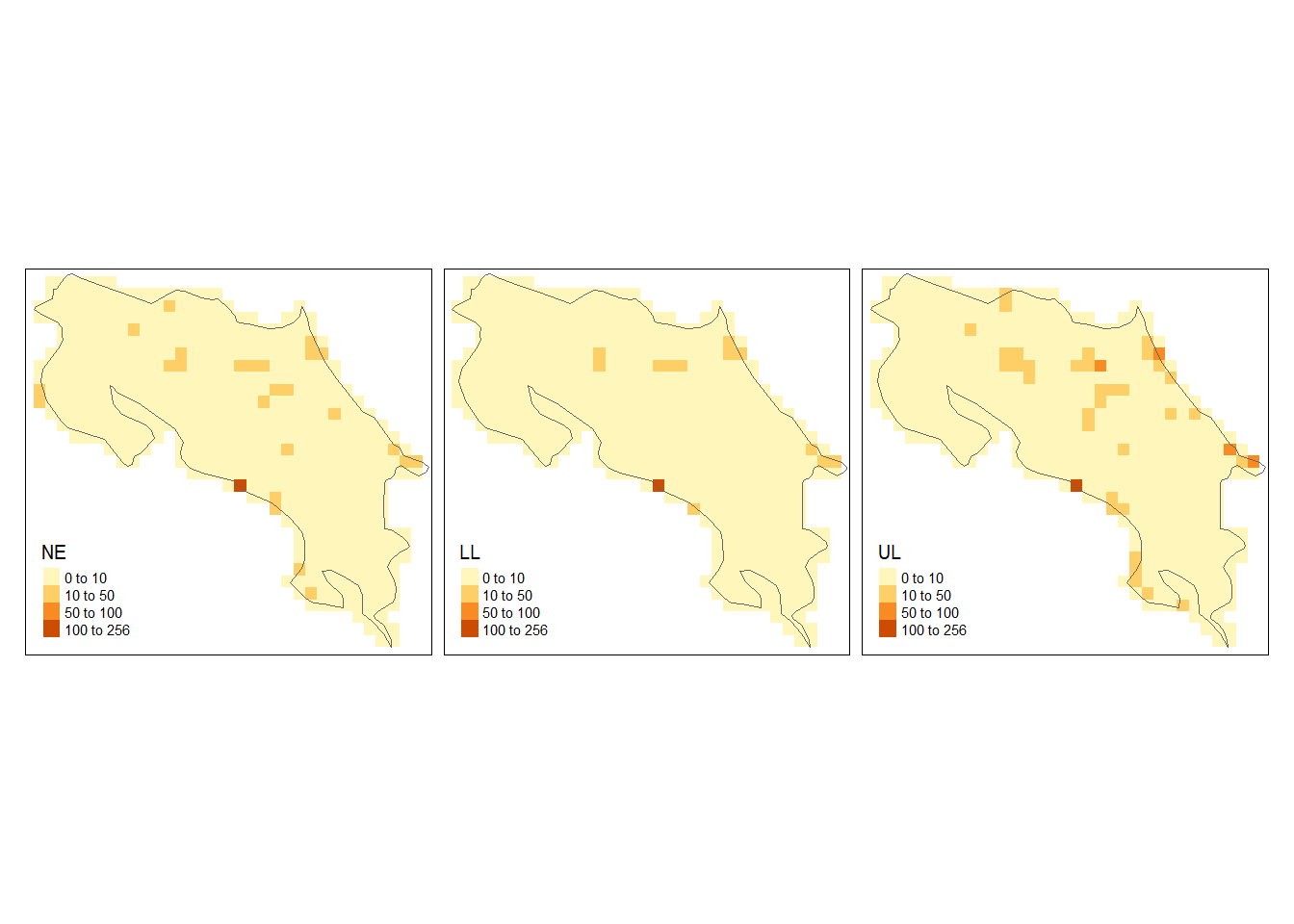
We observe that overall, the intensity of sloth occurrence is low, with less than 10 sloths in each of the cells. There are also some locations of high sloth intensity in the west and east coasts and the north of Costa Rica. The maps with the lower and upper limits of 95% credible intervals denote the uncertainty of these predictions. These maps inform about the spatial patterns in the period where the data were collected. In addition, maps of the sloth numbers over time can also be produced using spatio-temporal point process models and this will help understand spatio-temporal patterns. These results can be useful for decision-makers to identify areas of interest for conservation management strategies.
6 Discussion
Species distribution models are widely used in ecology for conservation management of species and their environments. In this paper, we have described a log-Gaussian Cox process that can be used to model species occurrence data, and assess the effect of spatial explanatory variables, and how to fit the model using the R-INLA package. We have illustrated the modeling approach using sloth occurrence data in Costa Rica that retrieved from the Global Biodiversity Information Facility database (GBIF) using the spocc package and a spatial climatic variable obtained with the geodata package. We have also shown how to examine and interpret the results including the estimates of the parameters and the intensity of the process, and how to create maps of variables of interest using the tmap package.
The objective of this paper is to illustrate how to analyze species occurrence data using spatial point process models and cutting-edge statistical techniques in R. Therefore, we have ignored the data collection methods and have assumed that the spatial pattern analyzed is a realization of the true underlying process that generates the locations. In real investigations, however, it is important to understand the sampling mechanisms, and assess potential biases in the data such as overrepresentation of certain areas that can invalidate inferences. Ideally, we would use data that have been obtained using well-defined sampling schemes. Alternatively, we would need to develop models that adjust for data biases to produce meaningful results. Moreover, expert knowledge is crucial to be able to develop appropriate models that include important predictive covariates and random effects that account for different types of variability.
To conclude, this paper provides an accessible illustration of spatial point process models and computational approaches that can help non-statisticians analyze spatial point patterns using R. We have shown how to use these approaches in the context of species distribution modeling, but they are also useful to analyze spatial data that arise in many other fields such as epidemiology or the environment.

This work by Paula Moraga is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
7 References
Moraga, P. Species Distribution Modeling using Spatial Point Processes: a Case Study of Sloth Occurrence in Costa Rica. The R Journal, 12(2):293-310, 2020 https://journal.r-project.org/archive/2021/RJ-2021-017/RJ-2021-017.pdf
Moraga, P. (2019). Geospatial Health Data: Modeling and Visualization with R-INLA and Shiny. Chapman & Hall/CRC Biostatistics Series, http://www.paulamoraga.com/book-geospatial
Moraga, P. (2023). Spatial Statistics for Data Science: Theory and Practice with R. Chapman & Hall/CRC Data Science Series, http://www.paulamoraga.com/book-spatial