8 Spatial autocorrelation
Spatial autocorrelation is used to describe the extent to which a variable is correlated with itself through space. This concept is closely related to Tobler’s First Law of Geography, which states that “everything is related to everything else, but near things are more related than distant things” (Tobler 1970). Positive spatial autocorrelation occurs when observations with similar values are closer together (i.e., clustered). Negative spatial autocorrelation occurs when observations with dissimilar values are closer together (i.e., dispersed). Figure 8.1 shows three configurations of areas showing different types of spatial autocorrelation.


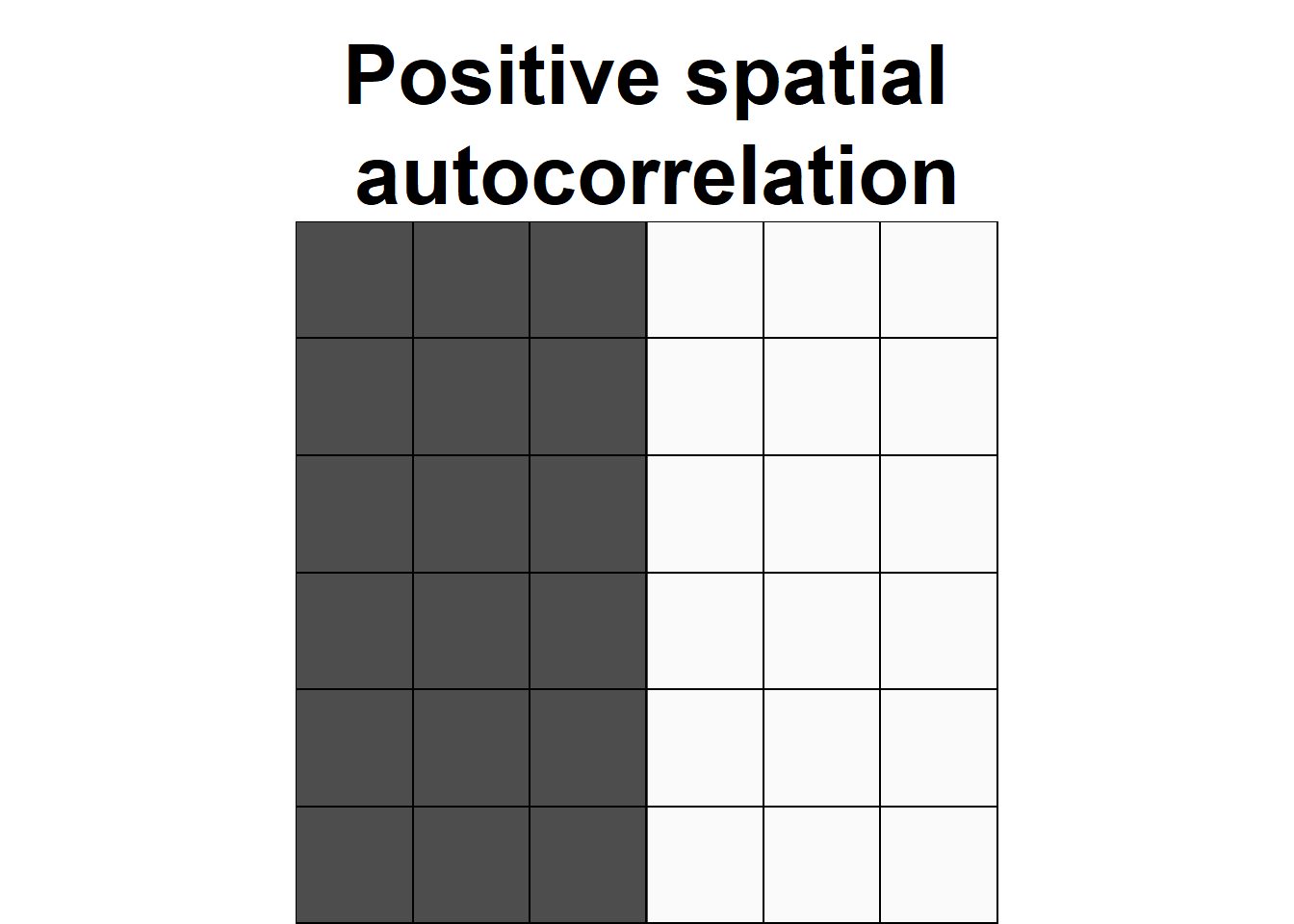
FIGURE 8.1: Examples of configurations of areas showing different types of spatial autocorrelation.
Spatial autocorrelation can be assessed using indices that summarize the degree to which similar observations tend to occur near each other over the study area. Two common indices that are used to assess spatial autocorrelation in areal data are Moran’s \(I\) (Moran 1950) and Geary’s \(C\) (Geary 1954).
In this chapter, we use the Moran’s \(I\) to test the spatial autocorrelation of housing prices in 506 census tracts in Boston, USA, in 1978 obtained from the spData package (Bivand, Nowosad, and Lovelace 2022).
The data has a variable called MEDV with the median prices of owner-occupied housing in $1000 USD.
We create the variable vble with the values of MEDV that will be used in the analysis.
Figure 8.2 shows the map created with the housing prices using mapview (Appelhans et al. 2022).
library(spData)
library(sf)
library(mapview)
map <- st_read(system.file("shapes/boston_tracts.shp",
package = "spData"), quiet = TRUE)
map$vble <- map$MEDV
mapview(map, zcol = "vble")FIGURE 8.2: Median prices of owner-occupied housing in $1000 USD in census tracts of Boston in 1978.
8.1 Global Moran’s \(I\)
The Global Moran’s \(I\) (Moran 1950) takes the form
\[I = \frac{n \sum_i \sum_j w_{ij}(Y_i - \bar Y)(Y_j - \bar Y)} {(\sum_{i \neq j} w_{ij}) \sum_i (Y_i - \bar Y)^2},\]
where \(n\) is the number of regions, \(Y_i\) is the observed value of the variable of interest in region \(i\), and \(\bar Y\) is the mean of all values. \(w_{ij}\) are spatial weights that denote the spatial proximity between regions \(i\) and \(j\), with \(w_{ii} = 0\) and \(i, j=1,\ldots,n\). The definition of the spatial weights depends on the variable of study and the specific setting.
We can test the presence of spatial autocorrelation using the Moran’s \(I\), which quantifies how similar each region is with its neighbors and averages all these assessments. Under the null hypothesis of no spatial autocorrelation, observations \(Y_i\) are independent identically distributed, and \(I\) is asymptotically normally distributed with mean and variance equal to
\[E[I] = \frac{-1}{n-1}\] and \[Var[I] = \frac{n^2(n-1)S_1 - n(n-1)S_2 - 2 S_0^2}{(n+1)(n-1)^2 S_0^2},\] where
\[S_0 = \sum_{i \neq j} w_{ij},\ S_1= \frac{1}{2}\sum_{i\neq j} (w_{ij}+w_{ji})^2\mbox{ and } S_2 = \sum_k \left(\sum_j w_{kj}+\sum_i w_{ik}\right)^2.\]
Moran’s \(I\) values usually range from –1 to 1. Moran’s \(I\) values significantly above \(E[I] = -1/(n-1)\) indicate positive spatial autocorrelation or clustering. This occurs when neighboring regions tend to have similar values. Moran’s \(I\) values significantly below \(E[I]\) indicate negative spatial autocorrelation or dispersion. This happens when regions that are close to one another tend to have different values. Finally, Moran’s \(I\) values around \(E[I]\) indicate randomness, that is, absence of spatial pattern.
When the number of regions is sufficiently large, \(I\) has a normal distribution and we can assess whether any given pattern deviates significantly from a random pattern by comparing the z-score
\[z = \frac{I-E(I)}{Var(I)^{1/2}}\]
to the standard normal distribution. An alternative approach to judge significance is Monte Carlo randomization. This method creates random patterns by reassigning the observed values among the areas and calculates the Moran’s \(I\) for each of the patterns, providing a randomization distribution for the Moran’s \(I\). If the observed value of Moran’s \(I\) lies in the tails of this distribution, the assumption of independence among observations is rejected. Thus, we can test spatial autocorrelation by following these steps:
State the null and alternative hypotheses:
\(H_0: I = E[I]\) (no spatial autocorrelation),
\(H_1: I \neq E[I]\) (spatial autocorrelation).Choose the significance level \(\alpha\) we are willing to tolerate, which represents the maximum value for the probability of incorrectly rejecting the null hypothesis when it is true (usually \(\alpha = 0.05\)).
Calculate the test statistic:
\[z = \frac{I-E(I)}{Var(I)^{1/2}}.\]Find the p-value for the observed data by comparing the z-score to the standard normal distribution or via Monte Carlo randomization. The p-value is the probability of obtaining a test statistic as extreme as or more extreme than the one observed test statistic in the direction of the alternative hypothesis, assuming the null hypothesis is true.
Make one of these two decisions and state a conclusion:
If p-value \(< \alpha\), we reject the null hypothesis. We conclude data provide evidence for the alternative hypothesis.
If p-value \(\geq \alpha\), we fail to reject the null hypothesis. The data do not provide evidence for the alternative hypothesis.
8.2 The moran.test() function
The function moran.test() of the spdep package can be used to test spatial autocorrelation using Moran’s \(I\).
The arguments of moran.test() are a numeric vector with the data, a list with the spatial weights, and the type of hypothesis.
The argument that denotes the hypothesis is called alternative and can be set equal to greater (default), less or two.sided to represent a different alternative hypothesis.
In this example, we specify the null and alternative hypothesis as follows:
\(H_0: I \leq E[I]\) (negative spatial autocorrelation or no spatial autocorrelation),
\(H_1: I > E[I]\) (positive spatial autocorrelation).
We use moran.test() to test this hypothesis by setting alternative = "greater".
The list with the spatial weights is calculated by first obtaining the neighbors of each area with the poly2nb() function, and then creating a list containing the neighbors with the nb2listw() function of spdep.
# Neighbors
library(spdep)
nb <- poly2nb(map, queen = TRUE) # queen shares point or border
nbw <- nb2listw(nb, style = "W")
# Global Moran's I
gmoran <- moran.test(map$vble, nbw,
alternative = "greater")
gmoran
Moran I test under randomisation
data: map$vble
weights: nbw
Moran I statistic standard deviate = 23, p-value
<2e-16
alternative hypothesis: greater
sample estimates:
Moran I statistic Expectation Variance
0.6266754 -0.0019802 0.0007249
gmoran[["estimate"]][["Moran I statistic"]] # Moran's I[1] 0.6267
gmoran[["statistic"]] # z-scoreMoran I statistic standard deviate
23.35
gmoran[["p.value"]] # p-value[1] 6.923e-121The object returned by moran.test() provides the Moran’s \(I\) statistic, the z-score and the p-value.
We observe the p-value obtained is lower than the significance level 0.05.
Then, we reject the null hypothesis and conclude there is evidence for positive spatial autocorrelation.
The same conclusion is obtained if we use a Monte Carlo approach to assess significance.
This approach creates random patterns by reassigning the values among the fixed areas and calculates the Moran’s \(I\) for each of these patterns. Then, it calculates the p-value as the proportion of values as extreme or more extreme than the statistic observed in the direction of the alternative hypothesis.
Here, we conduct a
Monte Carlo randomization approach using the moran.mc() function setting the number of simulations to nsim = 999.
Figure 8.3 shows the histogram of the Moran’s \(I\) values for each of the simulated patterns, as well as the Moran’s \(I\) obtained with the real data.
We observe a p-value lower than 0.05 indicating that the data presents positive spatial autocorrelation.
gmoranMC <- moran.mc(map$vble, nbw, nsim = 999)
gmoranMC
Monte-Carlo simulation of Moran I
data: map$vble
weights: nbw
number of simulations + 1: 1000
statistic = 0.63, observed rank = 1000, p-value
= 0.001
alternative hypothesis: greater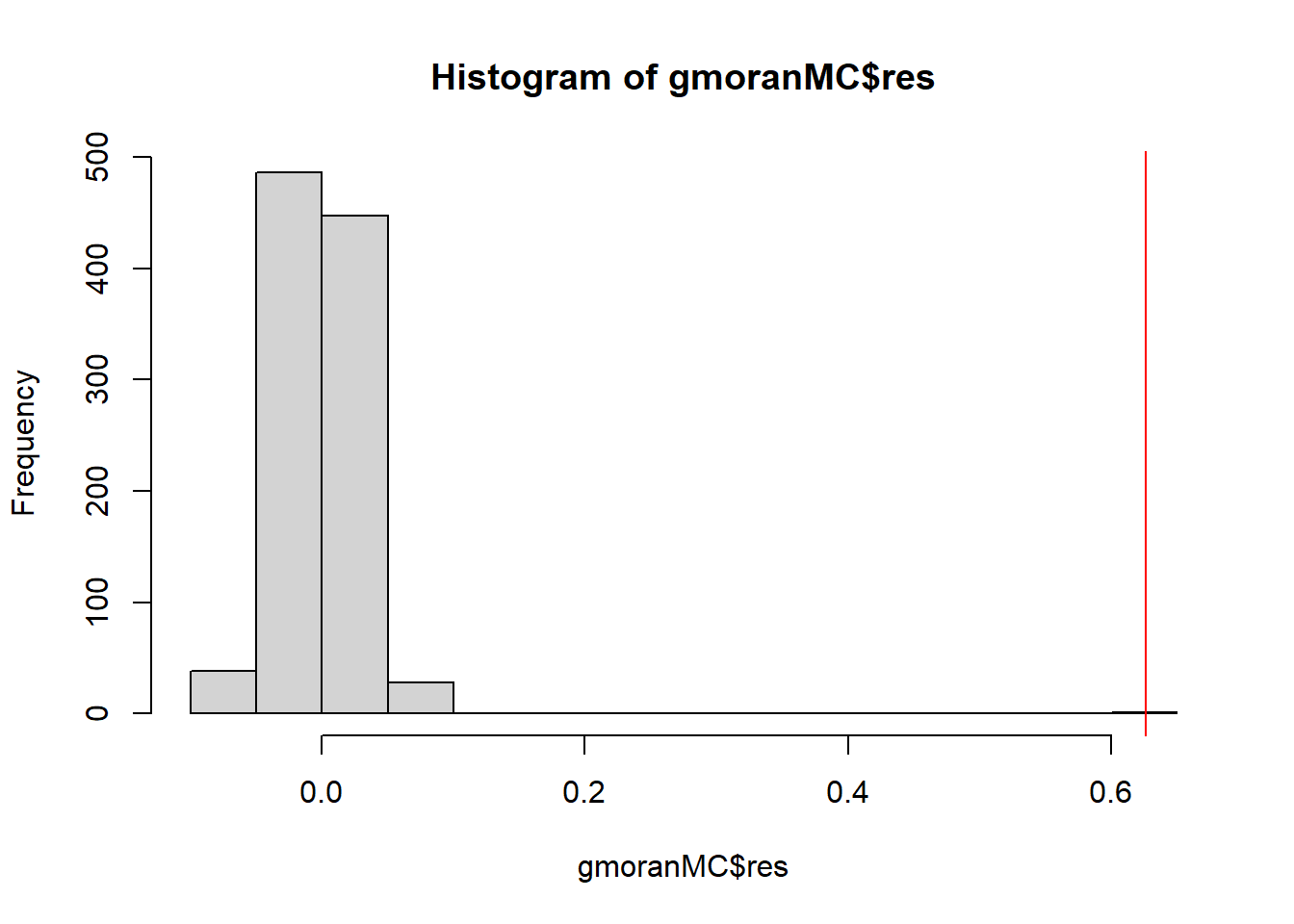
FIGURE 8.3: Histogram of the Moran’s \(I\) values for each of the simulated patterns in the Monte Carlo randomization approach. The red line represents the Moran’s \(I\) obtained for the real data.
8.3 Moran’s \(I\) scatterplot
The moran.plot() function can be used to construct a Moran’s \(I\) scatterplot to visualize the spatial autocorrelation in the data.
This plot displays the observations of each area against its spatially lagged values.
The spatially lagged value for a given area is calculated as a weighted average of the neighboring values for that area. This value can be computed, for example, using the lag.listw() function of spdep passing the values and the spatial weights corresponding to the areas.
Figure 8.4 shows the Moran’s \(I\) scatterplot for the housing prices data obtained with the moran.plot() function passing the housing prices and the spatial weights corresponding to the Boston tracts.
We observe a positive linear relationship between the observations and their spatially lagged values.
Using this plot, we can also identify data points that have a high influence on the linear relationship between the data and the lagged values.
moran.plot(map$vble, nbw)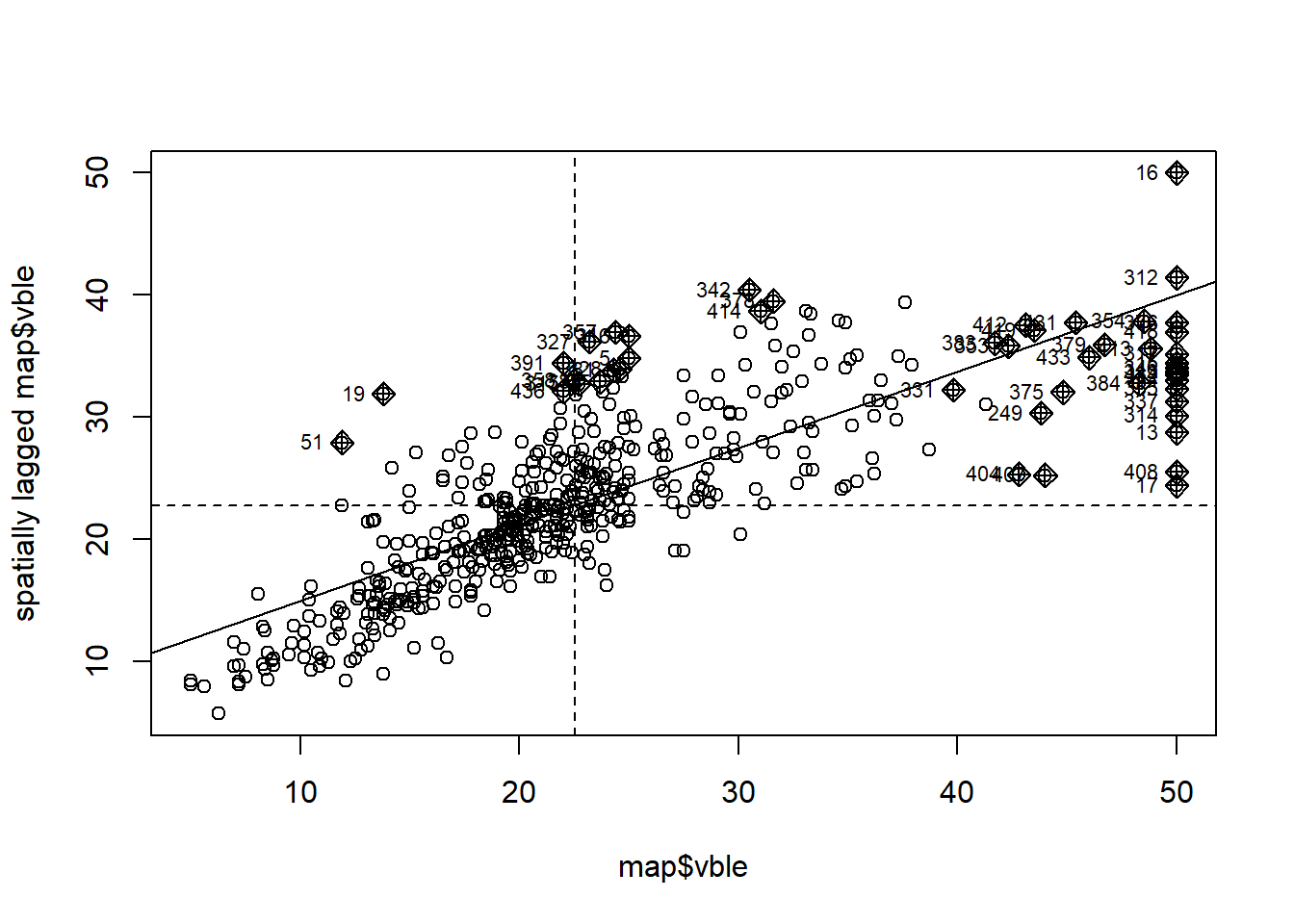
FIGURE 8.4: Moran’s \(I\) scatterplot showing the observations against its spatially lagged values.
8.4 Local Moran’s \(I\)
We have seen that the Global Moran’s \(I\) provides an index to assess the spatial autocorrelation for the whole study region. There is often interest in providing a local measure of similarity between each area’s value and those of nearby areas. Local Indicators of Spatial Association (LISA) (Anselin 1995) are designed to provide an indication of the extent of significant spatial clustering of similar values around each observation. A desirable property is that the sum of the LISA’s values across all regions is equal to a multiple of the global indicator of spatial association. As a result, global statistics may be decomposed into a set of local statistics and most LISAs are defined as local versions of well-known global indexes.
One of the most popular LISAs is the local version of Moran’s \(I\). For the \(i\)th region, the local Moran’s \(I\) defined as
\[I_i = \frac{n (Y_i - \bar Y)}{\sum_j (Y_j - \bar Y)^2} \sum_j w_{ij}(Y_j - \bar Y).\]
Note that the global Moran’s \(I\) is proportional to the sum of the local Moran’s \(I\) obtained for all regions:
\[I = \frac{1}{\sum_{i \neq j} w_{ij}}\sum_i I_i.\]
Typically, the values of the LISAs are mapped to indicate the location of areas with comparatively high or low local association with neighboring areas. A high value for \(I_i\) suggests that the area is surrounded by areas with similar values. Such an area is part of a cluster of high observations, low observations, or moderate observations. A low value for \(I_i\) indicates that the area is surrounded by areas with dissimilar values. Such an area is an outlier indicating that the observation of area \(i\) is different from most or all of the observations of its neighbors.
To interpret the local Moran’s \(I\) for each of the areas, it is necessary to compute a map of p-values representing the probability of exceeding the observed values assuming the null hypothesis is true. These p-values, regardless of the presence or absence of global spatial association, may be obtained by a simulation process with a conditional randomization approach. In this approach, the observed value \(Y_i\) at region \(i\) is fixed, and the remaining values are randomly reassigned over the other regions.
8.5 The localmoran() function
The localmoran() function of the spdep package can be used to compute the Local Moran’s \(I\) for a given dataset.
The arguments of localmoran() include a numeric vector with the values of the variable, a list with the neighbor weights, and the name of an alternative hypothesis that can be set equal to greater (default), less or two.sided.
The returned object of the localmoran() function contains the following information:
-
Ii: Local Moran’s \(I\) statistic for each area, -
E.Ii: Expectation Local Moran’s \(I\) statistic, -
Var.Ii: Variance Local Moran’s \(I\) statistic, -
Z.Ii: z-score, -
Pr(z > E(Ii)),Pr(z < E(Ii))orPr(z != E(Ii)): p-value for an alternative hypothesisgreater,lessortwo.sided, respectively.
Here, we use the localmoran() function to compute the Local Moran’s \(I\) for the housing prices data.
We set alternative = "greater" which corresponds to testing
\(H_0\): no or negative spatial autocorrelation vs.
\(H_1\): positive spatial autocorrelation.
lmoran <- localmoran(map$vble, nbw, alternative = "greater")
head(lmoran) Ii E.Ii Var.Ii Z.Ii
1 -0.3457508 -5.254e-04 3.275e-02 -1.9075
2 0.0175875 -1.627e-05 2.046e-03 0.3892
3 0.0123380 -6.557e-07 4.090e-05 1.9294
4 -0.0001654 -1.059e-07 1.332e-05 -0.0453
5 0.3591629 -1.428e-04 7.899e-03 4.0428
6 0.0545611 -1.626e-04 1.357e-02 0.4697
Pr(z > E(Ii))
1 9.718e-01
2 3.486e-01
3 2.684e-02
4 5.181e-01
5 2.641e-05
6 3.193e-01We create maps with tmap (Tennekes 2022) showing the housing prices, the local Moran’s \(I\), z-scores, and p-values.
Areas with p-value less than the significance level 0.05 (or with z-scores higher than qnorm(0.95) = 1.65) correspond to areas for which we would reject the null hypothesis and conclude they present positive spatial autocorrelation.
map$lmI <- lmoran[, "Ii"] # local Moran's I
map$lmZ <- lmoran[, "Z.Ii"] # z-scores
# p-values corresponding to alternative greater
map$lmp <- lmoran[, "Pr(z > E(Ii))"]
p1 <- tm_shape(map) +
tm_polygons(col = "vble", title = "vble", style = "quantile") +
tm_layout(legend.outside = TRUE)
p2 <- tm_shape(map) +
tm_polygons(col = "lmI", title = "Local Moran's I",
style = "quantile") +
tm_layout(legend.outside = TRUE)
p3 <- tm_shape(map) +
tm_polygons(col = "lmZ", title = "Z-score",
breaks = c(-Inf, 1.65, Inf)) +
tm_layout(legend.outside = TRUE)
p4 <- tm_shape(map) +
tm_polygons(col = "lmp", title = "p-value",
breaks = c(-Inf, 0.05, Inf)) +
tm_layout(legend.outside = TRUE)
tmap_arrange(p1, p2, p3, p4)If we used alternative = "two.sided" instead of alternative = "greater", we would be testing
\(H_0\): no spatial autocorrelation vs.
\(H_1\): positive or negative spatial autocorrelation.
In this two-sided test,
z-score values lower than –1.96 indicate negative spatial autocorrelation, and z-score values greater than 1.96 indicate positive spatial autocorrelation.
The map below shows the areas with negative, no, and positive spatial autocorrelation, obtained by breaking the legend according to these z-score values.
8.6 Clusters
Local Moran’s \(I\) allows us to identify clusters of the following types:
- High-High: areas of high values with neighbors of high values,
- High-Low: areas of high values with neighbors of low values,
- Low-High: areas of low values with neighbors of high values,
- Low-Low: areas of low values with neighbors of low values.
To detect clusters, we first use the localmoran() function to calculate the local Moran’s \(I\).
The p-values for the alternative hypothesis "two.sided" are in column 5 of the returned object.
lmoran <- localmoran(map$vble, nbw, alternative = "two.sided")
head(lmoran) Ii E.Ii Var.Ii Z.Ii
1 -0.3457508 -5.254e-04 3.275e-02 -1.9075
2 0.0175875 -1.627e-05 2.046e-03 0.3892
3 0.0123380 -6.557e-07 4.090e-05 1.9294
4 -0.0001654 -1.059e-07 1.332e-05 -0.0453
5 0.3591629 -1.428e-04 7.899e-03 4.0428
6 0.0545611 -1.626e-04 1.357e-02 0.4697
Pr(z != E(Ii))
1 5.645e-02
2 6.971e-01
3 5.368e-02
4 9.639e-01
5 5.282e-05
6 6.386e-01
map$lmp <- lmoran[, 5] # p-values are in column 5Then, we identify the clusters of each type by using the information provided by the Moran’s \(I\) scatterplot obtained with the moran.plot() function (Figure 8.5).
mp <- moran.plot(as.vector(scale(map$vble)), nbw)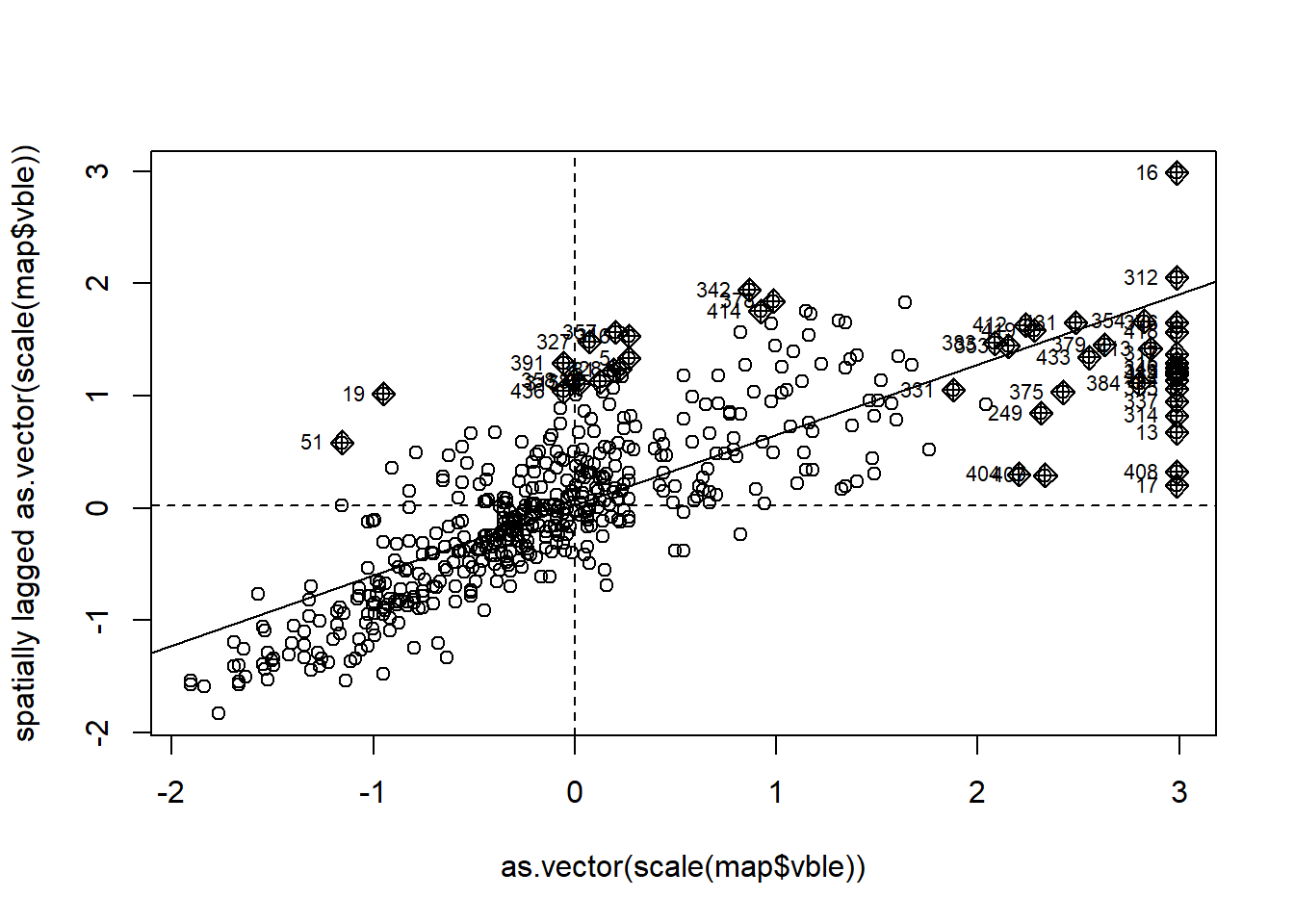
FIGURE 8.5: Moran’s \(I\) scatterplot showing the scaled values against its spatially lagged values.
head(mp) x wx is_inf labels dfb.1_
1 -0.514597 0.67056 FALSE 1 0.090885
2 -0.090551 -0.19384 FALSE 2 -0.015162
3 0.018179 0.67735 FALSE 3 0.060002
4 0.007306 -0.02259 FALSE 4 -0.004886
5 0.268258 1.33623 TRUE 5 0.107458
6 -0.286265 -0.19022 FALSE 6 -0.003359
dfb.x dffit cov.r cook.d hat
1 -4.682e-02 0.102234 0.9900 5.193e-03 0.002501
2 1.374e-03 -0.015224 1.0055 1.161e-04 0.001993
3 1.092e-03 0.060012 0.9987 1.798e-03 0.001977
4 -3.573e-05 -0.004886 1.0059 1.196e-05 0.001976
5 2.885e-02 0.111265 0.9832 6.131e-03 0.002119
6 9.624e-04 -0.003494 1.0061 6.115e-06 0.002139Specifically, we identify the cluster types by using the quadrants of the scaled values (mp$x) and their spatially lagged values (mp$wx), and the p-values obtained with the local Moran’s \(I\) for each of the areas (map$lmp).
The classification of the clusters is as follows. Areas with significant local Moran’s \(I\) are classified as high-high if both the value and its corresponding spatially lagged value are positive,
low-low if both the value and its spatially lagged value are negative,
high-low if the the value is positive and the spatially lagged value negative, and low-high is the value is negative and the spatially lagged value positive.
We create the variable quadrant denoting the type of cluster for each of the areas using
the quadrant corresponding to its value and its spatially lagged value, and the p-value.
Specifically, areas with quadrant equal to 1, 2, 3, and 4 correspond to clusters of type high-high, low-low, high-low, and low-high, respectively. Areas with quadrant equal to 5 are non-significant.
map$quadrant <- NA
# high-high
map[(mp$x >= 0 & mp$wx >= 0) & (map$lmp <= 0.05), "quadrant"]<- 1
# low-low
map[(mp$x <= 0 & mp$wx <= 0) & (map$lmp <= 0.05), "quadrant"]<- 2
# high-low
map[(mp$x >= 0 & mp$wx <= 0) & (map$lmp <= 0.05), "quadrant"]<- 3
# low-high
map[(mp$x <= 0 & mp$wx >= 0) & (map$lmp <= 0.05), "quadrant"]<- 4
# non-significant
map[(map$lmp > 0.05), "quadrant"] <- 5The map below shows the clusters obtained with the Boston housing prices data.
tm_shape(map) + tm_fill(col = "quadrant", title = "",
breaks = c(1, 2, 3, 4, 5, 6),
palette = c("red", "blue", "lightpink", "skyblue2", "white"),
labels = c("High-High", "Low-Low", "High-Low",
"Low-High", "Non-significant")) +
tm_legend(text.size = 1) + tm_borders(alpha = 0.5) +
tm_layout(frame = FALSE, title = "Clusters") +
tm_layout(legend.outside = TRUE)